
There's been a lot of discussion on social media of a recent paper in PNAS by Anders Eklund, Tom Nichols, and Hans Knutsson. Cluster failure: Why fMRI inferences for spatial extent have inflated false-positive rates.
Even Science magazine felt they needed to address it. What is this fuss all about? The abstract states that commonly used methods can result in "false-positive rates of up to 70%", and concludes that the "results question the validity of some 40,000 fMRI studies", i.e., almost all published studies using fMRI. Some social media commentators have jumped on this statement to trash much basic human research using functional magnetic resonance imaging (fMRI). I'll discuss in a few paragraphs the technical issue they raise, but first let's clarify i) how many studies are actually affected by the critique of Eklund et al, and ii) how bad the errors are in those studies.
First, how many studies are affected? Most published studies have used one of the software packages tested in this paper, but most studies do not use the specific procedures with the high false positive rates flagged by Eklund et al. The "up to 70%" means that for certain kinds of cluster comparisons, up to 70% of studies using the default settings of the procedures in the common software packages would incorrectly identify at least one region as differently activated (a false positive). That's the figure that many commenters jumped on. However only a few studies use the settings that produced the headline 70% proportion of studies with false positives; Eklund et al found more typically 10% - 20% of more common one-sample cluster inferences tests (their Figure 1), which are performed to assess which regions are activated during a task, would have a false positive. One of the authors, Tom Nichols, has re-calculated and clarified how many studies are called into question at: http://blogs.warwick.ac.uk/nichols/entry/bibliometrics_of_cluster/
He estimates about 10% of published studies use the kind of cluster testing that the Eklund study directly critiques. He says he regrets the mention of 40,000 studies affected in the paper's abstract, and has posted a correction on PubMed Commons, and has submitted an erratum to PNAS.
Second, among those studies with a problem, how bad is the problem? Eklund et al estimated the proportions of studies using a particular data analysis method that would find at least one false region of activation. Note that most published studies find several dozen regions activated. The 10-30% rate (among the 10% of studies affected), is not the proportion of mistakes (false positives) among all regions identified by these studies, but rather the proportion of studies that report at least one false positive, among the many regions reported activated. Often the number of false positives in any individual study follows something close to a geometric distribution (that means, the probabilities of one, two, three or more false positives, are proportional to a small number, its square, its cube, etc). In an online discussion among expert practitioners at Discover Blogs, Avniel Ghuman estimated a typical study (among the 10% of studies affected) may have between 0.3 and 1.2 false positives (among the several dozen reported). If you want to see the experts debate these issues among themselves, read this thread. http://blogs.discovermagazine.com/neuroskeptic/2016/07/07/false-positive-fmri-mainstream
Some commentators are using the phrase 'common software bug' to describe this paper. * Note that the major critique is about widely used methods; Eklund et al also uncovered a software bug in one analysis by the least-used software package, AFNI, which affects a tiny fraction of studies.
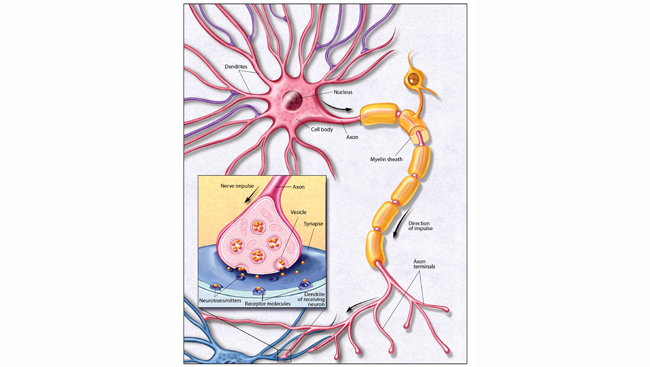
So what is the issue that Eklund et al address? Functional MRI (fMRI) measures how hard brain regions are working; a typical study measures summarizes the oxygen demand at 10,000 to 20,000 distinct locations in the brain; demand at each location reflects the work of a million or so neurons, averaged over a period of several seconds. Many fMRI studies compare activity of many locations in the brains of several human subjects under two (or more) conditions. There are many possible comparisons to be made (typically 10,000 to 20,000), using a statistical test, which gives a P-value for each location (this is known as 'multiple testing'). If scientists were to use the standard P < 5% significance threshold at each location, and if brain activity were the same between the two conditions (there no brain regions are consistently activated by the task), the tests would give p-values under 0.05, (P < 0.05) at 5% of all locations (500 - 1,000 locations) 'by chance'. Consider an analogy. If you throw a pair of dice the first time, and get two sixes, you may think you have a special talent. But if 100 ordinary people each throw a pair, very likely 2 to 4 people will throw a pair of sixes the first time. So in exploratory fMRI studies, where you are looking for activation anywhere in the brain, a more stringent threshold is needed for all tests to ensure that there is a low chance of wrongly declaring an activation at any one of the many locations tested across the brain (a false positive). (Setting this more stringent threshold also means that many real differences are missed.) A simple way to ensure this is to treat each location as if it were unrelated to every other location, and set the P-value threshold to 0.5 / 20,000 (the Bonferroni adjustment ).
Equivalently you may adjust the p-value of each test by multiplying by 20,000. However this threshold (or adjustment) is far too stringent (and would miss many real differences) because neurons in nearby locations usually work together on the same processes, and so become active together most of the time; but regions further away work on independent schedules - their work loads are typically not related. Furthermore a common data processing step is to average the activation measures at each location and its nearest neighbors, which increases correlation between each location and its neighbors. So in practice the adjustment should be based on the effective number of independent processes going on in the brain, not on the number of locations measured.
So then the problem for data analysts becomes how to estimate how many really independent processes are going on in the brain. This is equivalent to specifying exactly how correlated the activity at different locations is. Most of the commonly used data analysis software programs assume that the correlation between activity at different locations falls off with distance between them according to a simple elegant curve at all points in the brain. This is simple, and often nearly true, but clearly not true everywhere; the brain has structural boundaries, such as folds, across which activity is not correlated at all. The issue addressed by Eklund et al is how good is this simple approximation used by the commonly used data analysis programs. There are several kinds of tests done. The simplest test is to compare activity in all locations separately.
The Eklund et al paper finds no problems with any of the software packages on that comparison. However often researchers search for activation at a group of nearby locations (a 'cluster'). These tests are what the paper shows to have a higher rate of false positives. Eklund et al took real data from people at rest, not doing any particular task, and 'made up' an experimental design as if a task was being done in arbitrary time intervals, which Eklund et al made up. They then compared brain activity during the intervals selected as 'task' with activity during those selected as 'control'. Since no task was actually being done, brain activity during the time intervals selected as 'task' shouldn't look overall, any different from activity during 'control' times; statistical tests shouldn't declare any regions activated consistently across 20 subjects at p 0.02). However most studies report many (several dozen) areas activated. It is not the case that a large proportion of areas reported by these studies are false, rather that one or two reported areas are likely false in a small fraction of studies.
Eklund et al show that those studies, which search across the whole brain for differences in activation between two groups should be taken with more skepticism; a moderate fraction (perhaps 60%) may contain a false positive, again mostly those false positives will be the regions with adjusted p-value just barely under 0.05. In his blog post Tom Nichols points out that many earlier studies (mostly prior to 2000) did not even attempt to systematically correct for multiple comparisons, and simply compared the raw p-values at each location to a threshold of P < 0.001 (a guess as to the brain-wide stringent threshold). This is simply not strict enough, and most of these earlier studies (Nichols estimates 70%, see their Figure 2) could have several false positives. Again the false positives will be those near the stated threshold P < 0.001. In the past fifteen years most studies have used an explicit adjustment for multiple testing (which is almost, but not quite, good enough, as Eklund et al show.) Many studies test only regions that have been pre-chosen based on other studies; for these there is no multiple comparisons problem. However generally one should be cautious about basing strong statements on studies with p-values just under the commonly used significance threshold of .05, as has been shown in social psychology by the Reproducibility Project . So most of the fuss about the Eklund et al study is over-blown.
Some caution is always in order when considering results that are just barely statistically significant; the threshold P < 0.05 is often treated with superstitious reverence; it is not an imprimatur from the Statistical Vatican. While there are other significant limitations to FMRI studies, which I'll explore in later posts, the Eklund et al study does not invalidate twenty years of human brain research.










{kind=link}
{kind=link}