How AI Helps Us Understand Human Vision
- Published11 May 2020
- Author Nicoletta Lanese
- Source BrainFacts/SfN

The human brain has long been compared to an advanced computer, full of crisscrossing wires that pulse with electricity, carrying information from place to place. In fact, mathematician John von Neumann compared the physical parts of the nervous system to the vacuum tubes and other hardware comprising computers of the 1950s.
But even before von Neumann made such comparisons, computer scientists, including Alan Turing, began posing a fascinating and disturbing question: could computers someday function and “think” like humans? By the 60s and 70s, they began envisioning brain-inspired computer programs that would pave the way for modern artificial intelligence.
Today, the AI systems that were originally inspired by the brain are helping neuroscientists study the brain itself. They’ve become particularly important in studies of human visual perception.
In crafting systems to mimic human vision, engineers developed tools that help neuroscientists understand how we see the world. In turn, engineers are leveraging our growing knowledge of vision to improve their computer models and technologies. It’s a classic feedback loop.
The AI systems employed to model human vision are called neural networks, and they were inspired by simplified models of neurons in the brain, says Carnegie Mellon computer scientist David Held.
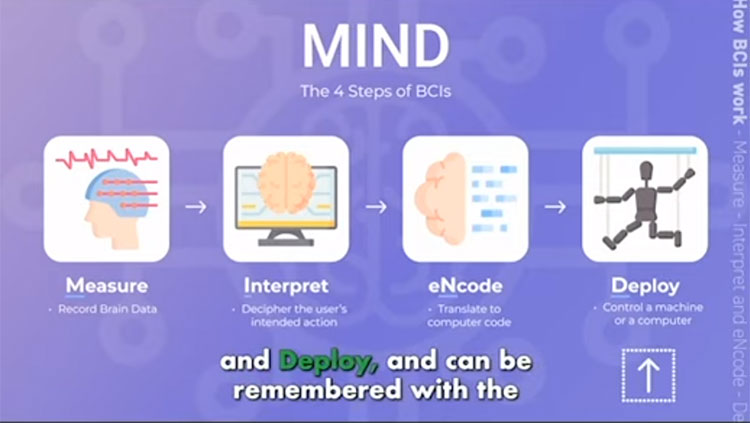
Neural networks were inspired by a simplified model of a neuron, which can be thought of as a “system that takes in inputs, multiplies the inputs by weights, and adds up the resulting values. If the sum exceeds a certain threshold, the output is ‘one,’ and if it’s below that threshold the output is ‘zero,’” Held explains. A “neuron” responds to a specific tidbit of information. Linked together, these neurons can tackle more complex problems, he said.
The visual cortex relies on linking together actual neurons. It is comprised of groups of neurons lying on top of each other like layers of an onion. Each progressive layer picks out more complex features of an image. For example, when you look at a tabby cat, neurons in your brain work together to analyze the animal’s shape then later identify its orange fur, pointed ears, triangular nose, and fuzzy tail. Activity across the whole network dictates what the system finally perceives.
In computing neural networks, nodes function as “neurons.” When triggered by incoming data, these bits of computer code send out a signal. Like neurons in the visual cortex, nodes can be grouped into stacked layers to create a “deep” neural network. Researchers are uncovering how each layer interacts with the next to arrive at a final output.
In 2012, a class of deep neural network called a convolutional neural network (CNN) showed success in computer vision, classifying images with unprecedented accuracy. As CNNs grew more popular, neuroscientists got in on the action.
Fordham University neuroscientist Elissa Aminoff notes these CNNs are doing so well in computer vision, that the question has become “do they reflect how the brain is processing [visual] information? What we started to do was…see whether the way these models represent an image is the same way that different areas of the brain represent an image.
CNN is a data hog. It becomes more accurate the more data it receives. The system “learns” by picking up patterns in that data, so it needs a lot of it. With that in mind, Aminoff’s team gathered brain scans from participants as each viewed roughly 5,000 images of objects and scenes.
The researchers will use their dataset to identify patterns in human brain activity that relate back to specific visual features and stimuli. According to Aminoff, computer vision models are helping neuroscientists “identify visual features and develop a visual vocabulary to talk about these images.
Brain activity patterns can guide the construction and testing of artificial neural network models that serve as hypotheses of how the organ works. “If the brain is a complicated system, you’re going to need complicated models,” says MIT neuroscientist James DiCarlo.
DiCarlo’s team attempted to model human vision by training neural networks on a library of one million images. Networks learned to recognize objects by strengthening or weakening connections between certain nodes. Then DiCarlo showed macaque monkeys a suite of new test images. Based on their computer model, the team could predict how certain neurons in the macaques’ brains would react to each image. They also developed new images with exaggerated features discovered by the model and found they could strongly activate certain subsets of neurons.
Critics of this computational method of neuroscience argue that the models can be as cryptic as the brain and may not reflect human brain function at all. However, DiCarlo says building models “becomes this virtuous cycle.” Scientists build an algorithm, test its accuracy by comparing its responses with the brain’s responses, refine their design, and test it again. Over time, they come closer to capturing reality.
About the Author

Nicoletta Lanese is a science writer with degrees in neuroscience and dance from the University of Florida and certificate in science communication from UC Santa Cruz. Based in NYC, she aims to bring science to new audiences, whether in print, online, or on stage.
CONTENT PROVIDED BY
BrainFacts/SfN
References
Chang, N., Pyles, J. A., Marcus, A., Gupta, A., Tarr, M. J., & Aminoff, E. M. (2019). BOLD5000, a public fMRI dataset while viewing 5000 visual images. Scientific Data, 6(1), 49. doi: 10.1038/s41597-019-0052-3
Gigerenzer, G. (2001). Digital Computer: Impact on the Social Sciences. In N. J. Smelser & P. B. Baltes (Eds.), International Encyclopedia of the Social & Behavioral Sciences (pp. 3684–3688). doi: 10.1016/B0-08-043076-7/00101-7
Miller, G. A. (2003). The cognitive revolution: A historical perspective. Trends in Cognitive Sciences, 7(3), 141–144. doi: 10.1016/S1364-6613(03)00029-9
Y. Li et al. (2019). Connecting Touch and Vision via Cross-Modal Prediction. CVPR 2019. http://visgel.csail.mit.edu/visgel-paper.pdf
Y. Li, J. Zhu, R. Tedrake, and A. Torralba, “Connecting Touch and Vision via Cross-Modal Prediction”, in IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Yang, Y., Tarr, M. J., Kass, R. E., & Aminoff, E. M. (2019). Exploring spatiotemporal neural dynamics of the human visual cortex. Human Brain Mapping, 40(14), 4213–4238. doi: 10.1002/hbm.24697