Data Driven: Making Sense of a Deluge of Information
- Published13 Feb 2018
- Reviewed13 Feb 2018
- Author Alexis Wnuk
- Source BrainFacts/SfN
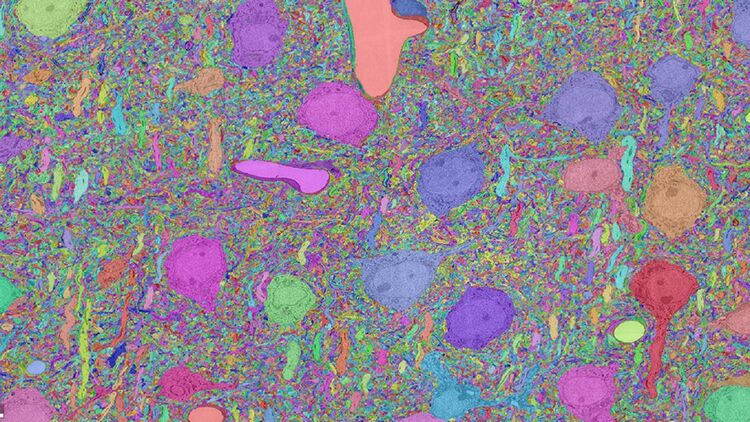
As the U.S. BRAIN Initiative and other large brain research projects around the world unravel the secrets of the brain, they are generating an unprecedented amount of data. For example, the artificial intelligence-focused ‘MICrONS’ program, funded by the Intelligence Advanced Research Projects Agency (IARPA), has generated six petabytes of electron microscopy data alone. That’s roughly the same amount of data as is contained in 78 years’ worth of HD video.
The sheer volume of data is difficult and expensive to store — storing the six petabytes of electron microscopy data costs $100,000 a month.
Logistical concerns are not the only challenges neuroscientists have to contend with. Making sense of all the data being collected will require ever more robust, reliable ways of analyzing and sharing it.
Often, our understanding of the brain is limited by the investigative tools we have at our disposal.
“Everything we do is because of this three-pound chunk of matter inside our heads,” says Loren Frank, Howard Hughes Medical Institute (HHMI) investigator at the Kavli Institute for Fundamental Neuroscience at the University of California, San Francisco. “The problem is, we fundamentally don’t understand it.”
Frank heads a collaborative project to build new tools and software that will improve the ways scientists record and decode brain signals. In 2014, the National Institutes of Health awarded the team a $2.5 million grant as part of the BRAIN Initiative to develop these tools.
Last year, the team unveiled a new software package for sorting data from multi-electrode brain recordings. Typically, researchers must manually comb through recording data to determine which electrical signals came from which cells. The new software, MountainSort, fully automates the process so that scientists can sort and analyze their ever-growing datasets faster and more accurately — and perhaps uncover new insights about the brain in the process.
“Sharing is going to accelerate the progress of the field”
Piecing insights together into a cohesive picture of the brain is difficult if scientists use different terminology to describe the same cells or processes. “Different people name cells in different ways. That causes confusion and a lot of debate,” says Hongkui Zeng, Executive Director of the Structured Science division at the Allen Institute for Brain Science in Seattle, Washington. Zeng directs a BRAIN Initiative-funded effort to develop a comprehensive atlas of cell types in the mouse brain. The project is part of the BRAIN Initiative Cell Census Network (BICCN). “The goal is to build a data-driven or evidence-based cell type taxonomy for the entire [science] community,” Zeng says. In other words — a common scientific language.
The resulting atlas will be made freely available to scientists. Collaborating and sharing data are vital to reconciling conflicting results and resolving scientific disagreements, Zeng says. “Sharing is going to accelerate the progress of the field,” she adds.
Worldwide collaboration and data-sharing might face technological constraints, but the biggest challenge might be cultural. “You can always build technology to facilitate sharing,” Zeng says. “The greatest barrier for sharing is really the culture. How do you recognize people’s contributions?” With fierce competition for coveted professorships and research grants, scientists may be reluctant to part with their data until their paper is published.
“That culture has to change,” says Terrence Sejnowski, HHMI investigator, and director of the computational neurobiological laboratory at the Salk Institute. The BRAIN Initiative tries to incentivize this cultural shift by requiring that all datasets be made publicly available as soon as possible, he adds.
Zeng notes that one of the very first discussions that took place in BICCN was about establishing a policy for collaboration and recognition in the publishing process. “Having this kind of common guideline will be really helpful to change the culture,” she says.
As a collaborative ethos becomes more pervasive, the tendency to share data may become more deeply ingrained, even instinctual. “When it’s a team effort, no one owns the data,” says Sejnowski. “And when no data is hoarded, everybody gains.”
About the Author

Alexis is a former staff writer/editor for BrainFacts. She graduated from the University of Pittsburgh in 2012 with degrees in neuroscience and English.
CONTENT PROVIDED BY
BrainFacts/SfN